Algoritmo de classificação K-Nearest Neighbors
01 May 2020 - Anthony João Bet
O site analyticsvidhya compilou em seu blog diversos projetos de machine learning, divididos em três níveis de dificuldade, iniciante, intermediário e avançado. Nesta série de tutorias iremos completar seis destes projetos/desafios, sendo eles, dois em cada nível de dificuldade. Cada projeto será dividido em dois artigos, um para explicar o algoritmo utilizado, e o outro para explicar como aplicar tal algoritmo no problema escolhido.
O primeiro projeto escolhido é o problema de classificação do banco de dados Iris. Este pequeno banco de dados é um clássico na área, e para atacar um problema tão simples iremos utilizar um algoritmo igualmente simples, chamado K-Nearest Neighbors (KNN).
K-Nearest Neighbors
Este algoritmo funciona de uma forma muito intuitiva, ele irá classificar um novo ponto comparando a posição deste ponto com a classe dos seus k vizinhos mais próximos.
Vejamos um exemplo, suponha que temos os seguintes dados:
dados = {
'red': [ [1,1],
[0,0],
[0,0.5]],
'blue': [ [2,2],
[2,1],
[3,4]]
}
novo_ponto = [1,2]
Esses dados possuem duas classes, ‘red’ e ‘blue’ e cada classe possui três pontos. Para classificar o novo ponto o algoritmo irá comparar a distancia entre o novo ponto e todos os outro pontos dos dados e então irá atribuir ao novo ponto a classe que pertencer à maioria dos seus K vizinhos mais próximos. Vamos plotar os dados e o novo ponto para entender melhor.
import matplotlib.pyplot as plt
plt.style.use('seaborn-whitegrid')
for k in dados:
[plt.scatter( ponto[0], ponto[1], c=k ) for ponto in dados[k] ]
plt.scatter( novo_ponto[0],novo_ponto[1], c='black')
plt.show()
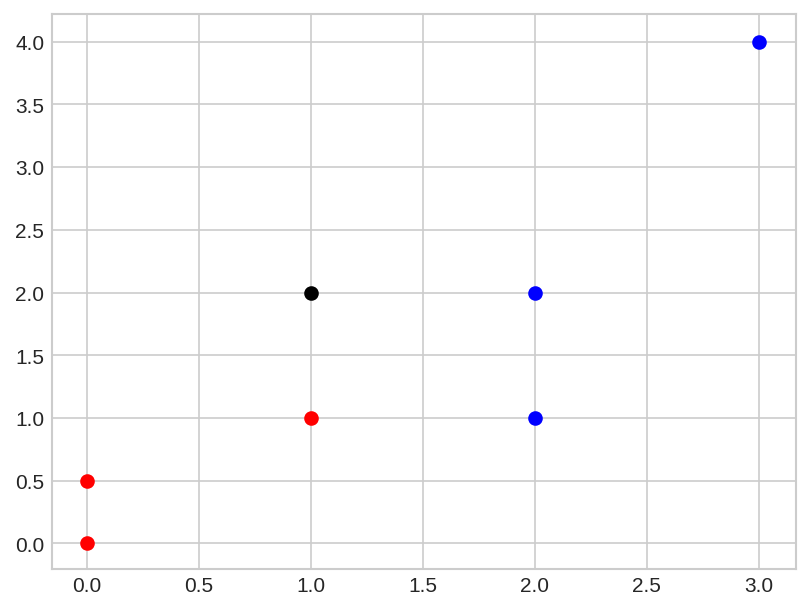
Se escolhermos k=3, vemos que os três vizinho mais próximos do novo ponto são dois pontos azuis e um ponto vermelho, dessa forma iremos classificar o novo ponto como um ponto da classe ‘blue’. Você deve ter cuidado quando for escolher um valor de K para que não haja empate no momento da contagem das classes. Por exemplo, se eu escolher k=2, em algum momento pode ser que os dois vizinhos mais próximos sejam um vermelho e um azul, dessa forma o algoritmo não terá como decidir qual é a classe do novo ponto.
Nós falamos sobre vizinhos mais próximos, então é natural que surja a pergunta: Qual a métrica utilizada para medir essas distâncias? A métrica utilizada irá depender to tipo de problema que estamos tentando resolver, por simplicidade iremos utilizar a distancia euclidiana.
A acuracia deste algoritimo é alta, mas ele não é eficiente para grandes quantidades de dados, já que em cada nova classificação é necessário calcular a distância entre o novo ponto e todos os pontos do dataset, para tentar contornar esse problema existem variações onde se calcula a distancia apenas com relação aos dados que estão dentro de um círculo centrado no novo ponto, isso aumenta bastante a eficiência do algoritmo.
No tutorial iremos utilizar o modulo KNeighborsClassifier da biblioteca Scikit-Learn. Com este módulo também é possível utilizar as variações do KNN e diversas métricas, não deixe de ler a documentação.
No próximo artigo iremos aplicar o KNN no banco de dados Iris. Obrigado pela leitura e até a próxima.